
程序员量化交易实战 12:回测不能只看最终收益
第十二篇补齐回测指标:总收益、年化收益、年化波动、类 Sharpe、最大回撤、胜率、盈亏比、换手率和交易次数,让策略比较有统一语言。
第 5 页。归档页按时间倒序展示,每页只加载一组文章封面,减少首屏压力。
第十二篇补齐回测指标:总收益、年化收益、年化波动、类 Sharpe、最大回撤、胜率、盈亏比、换手率和交易次数,让策略比较有统一语言。
第十一篇把第一个单标的回测扩展为多标的组合回测:等权分配资金、逐标的运行、聚合权益曲线、统计交易数量,并保留可测试边界。

公司里居然有两台闲置的 RTX 4090 机器,这篇记录如何把它们用起来:从 NVIDIA 驱动、代理服务、Ollama 部署、模型下载,到 API 测试和模型能力评估。

第十篇把行情清洗、因子信号和 A 股订单规则串起来,完成第一个可运行的信号回测循环,并对第 6-10 篇做阶段 review。

第九篇实现因子计算:用标准库计算日收益、均线、动量和年化波动率,并把结果转成 buy_watch、observe、risk_watch 三类可解释信号。

第八篇实现市场行情清洗:解析交易日和数字字段,校验 OHLC,去重,统一成交量单位,并输出覆盖率报告和被拒绝行的原因。

第七篇实现股票池构建:规范化股票代码、过滤 ST 和退市、去重、限制规模,并把公共 A 股股票池的构建过程写成可测试的纯函数。

第六篇进入 PostgreSQL 和 Alembic:为什么量化平台不能只靠内存对象,如何用 SQLAlchemy metadata 做 schema 巡检,并把表结构和迁移变成可测试的工程边界。

第五篇进入数据层:为什么策略之前必须先做数据源抽象、行情和财报数据、数据质量检查、来源记录和覆盖率。完成后对前五篇做第一次阶段 review。

第四篇把 A 股里的 100 股整数手、T+1、涨跌停、停牌、ST、手续费和印花税落到订单检查代码里,并在 ZiQuant 中新增可测试的 trading_rules 模块。

第三篇把股票池、K 线、复权、因子、信号、持仓、回测、最大回撤和 Sharpe 这些词翻译成 ZiQuant 里的模型、字段和测试对象,避免后面写代码时概念混用。

Cursor 的 Composer 2 在实际使用中可以触发生图,而官方 changelog 指向 Google Nano Banana Pro。本文记录这种编程工具里的生图工作流、成本判断,并用 Codex 生成图做同画幅对比。

第二篇把 ZiQuant 的 Python 工程骨架搭起来:目录、pyproject.toml、.env、配置读取、健康检查和测试命令。先让项目可安装、可启动、可验证,再进入数据层。
量化交易不是玄学,也不是靠一个指标躺赚。第一篇先把交易问题拆成程序员熟悉的数据、规则、验证和风控问题,并用 ZiQuant 项目完成可运行的第一步。
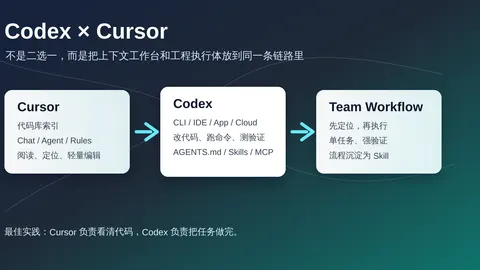
从 Codex 与 Cursor 的产品边界讲起,比较 Codex IDE、Codex CLI、Cursor 中 Codex 插件的优缺点,回答 Skills 与 Cursor 会话上下文能否互通,并给出一套实用的共生工作流。
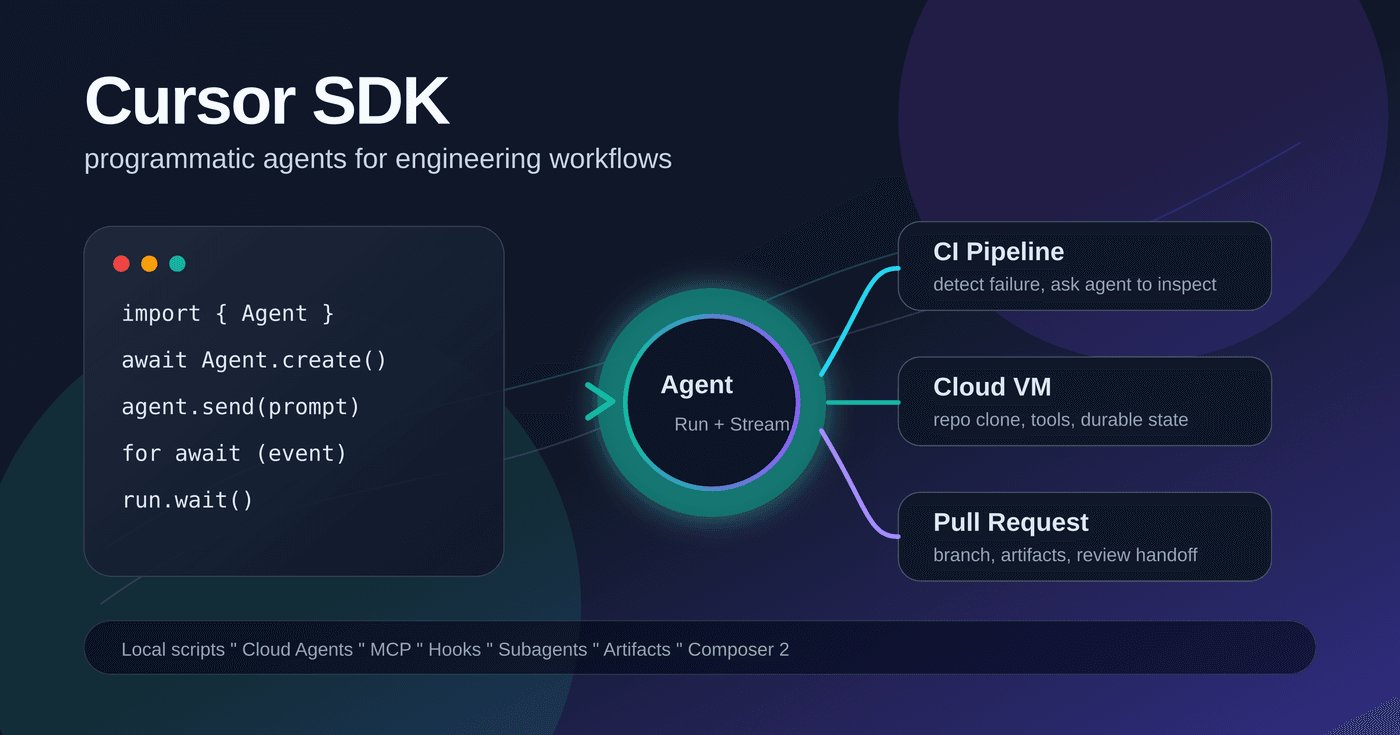
Cursor 新发布的 TypeScript SDK 把 IDE、CLI 和 Cloud Agents 背后的 agent 能力开放成可编程接口。本文梳理它的运行时、hooks、MCP、示例仓库和适用场景,并用一个 CI 自动修复失败 PR 的例子说明怎么落地。

向量检索不是把所有字段拼起来扔给 embedding 模型就结束了。本文用一个虚构的 API 工具市场做例子,拆解噪声文本、长描述、URL、阈值、混合召回和评估集如何影响检索质量,并总结一套可复用的最佳实践。

屏幕、CPU、网络与后台如何影响阅读类 App 耗电;原生与跨端取舍、长文本分段与列表虚拟化、深色与亮度策略;开源阅读器(KOReader、Librera、Readest、Legado 等)能否直接满足需求及许可证注意点。